What is Predictive Analytics
You are seated in your car, and on your way to a meeting. You feed in the destination, and Google Maps gives you directions. You are midway when Google Maps sounds an alert – there has been an accident ahead, and this could lead to traffic jams on the route. That piece of information is just-in-time for you to make a detour.
“Throughout the life-cycle of Hurricane Harvey, Weather Analytics published its 10-day ensemble hurricane forecast model, Beacon, to anticipate storm movements. This model helped track Hurricane Harvey before it made the landfall.” [Source]
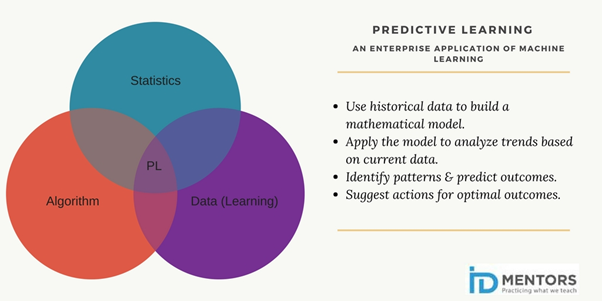
Let’s analyze the two examples. What made it possible for Google Maps to predict a traffic jam, and Weather Analytics to forecast the trajectory of Hurricane Harvey? At the very basic level, a combination of the following: Data, Algorithm and Statistical Modeling. And, how were these predictions useful? Well, it helped in minimizing risk. Predictive Analytics is a technique of Machine Learning (ML) in which a software program (agent) tries to build a model of its environment (Systems Network, Agents and Users) by trying out different actions under various circumstances. The software program or algorithm gets smarter in time based on the data that you feed it. Here is an analogy to help you understand how a program gets smarter – when you teach a young child the concept of animal by citing various examples, such as dog and cat, over time the child becomes smarter and is able to identify many other animals, such as cow, monkey etc. on her own. So, the concept of machines getting smarter on their own is known as Artificial Intelligence (AI). Predictive Analytics is a form of AI.
How is Predictive Analytics related to AI and ML
AI refers to the concept of machines being smart to carry out tasks on their own. ML is an application of AI based around the idea that machines should be given access to data, which they should use to learn, and get smarter. Predictive Analytics is a common enterprise application of ML.
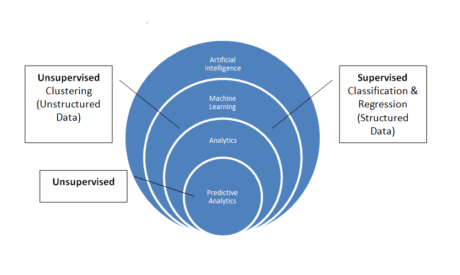
As you can see from the diagram, there are two types of ML – Supervised and Unsupervised. Supervised technique is applied to structured data using Classification and Regression algorithms. Unsupervised technique is applied to unstructured data using Clustering algorithms.
Classification, Regression and Clustering
Classification and regression are supervised data mining techniques.
- Classification: The main goal of classification is to identify the target class/category. This could be binary classification or multi-class classification. For example, “from a given email, predict whether it’s spam email or not”.
- Regression: The main goal of regression is to identify the relationship between two variables. Regression is numerical in nature. For example, “given the area of a house predict its market price”.
- Clustering: Clustering is an unsupervised data mining technique. Clustering algorithms are designed to find and group data with natural similarities. This is used when there are no obvious natural groupings, in which case the data may be difficult to explore (known as noisy data). Clustering the data can help us discover new groups and categories which we were unaware of previously.
Here is an analogy to better understand the three techniques. Think of Classification and Regression as Objective Questions, with Finite options – True/False or Multiple Choice. Think of Clustering as an Open-Ended question – with many possible answers!
What is Predictive Learning?
Now, let’s think of applying all this – AI, ML and Predictive Analytics to learning. To do so, let’s answer a few questions
- Can we get learning data? Yes. With most organizations and institutions using LMSs, there is definitely a lot of data.
- Can this data be used to optimize the learning process? The data can be used in many ways. It may be used to identify “at risk” learners so that interventions may be made just-in-time. It may also help us Identify early trends on programs and warn instructors if it is ineffective, and so on.
Predictive Analytics can be applied to any domain, and when applied to learning, it is called Predictive Learning Analytics (PLA).
Learning Data for Predictive Analytics
There are three common kinds of learning data, which we can retrieve from LMSs for predictive analytics. These are: activity data, achievement data, and static data.
- The LMS provides vast amounts of data about learner interactions with content, assessments, discussions with subject-matter experts and peers, and so on. This data is known as Activity Data.
- The LMS also provides a rich set of Achievement Data. This includes marks obtained in online assessments, as well as information from mid-term and annual performance appraisals. These performance indicators are very useful when you analyze learner/employee success in a specific program, and how well he/she is able to apply learning from these programs in workplace situations.
- Finally, there is Static Data. This data as the name suggests, does not change. It includes information such as, name, age, date-of-joining, educational qualifications, and so on. This data in relation with data about the employee performance and growth trajectory over time can help in identifying courses and programs that new employees with a similar profile should take.
Applying Predictive Analytics in Learning Systems
Imagine you have rolled out new training on the organizational LMS and you want to know which learners/employees are likely to default on completing the training this quarter. In this situation, you will use the data on learners who have dropped out in the past as build/training data to generate a classification model. You then run that model on the learners you’re curious about. The algorithms will look for learners whose attributes match the attribute patterns of previous drop-outs/non-drop-outs, and categorize them according to which group they most closely match. You can then use these groupings as indicators of which learners are most likely to default, and design interventions to address the “at risk” learners.
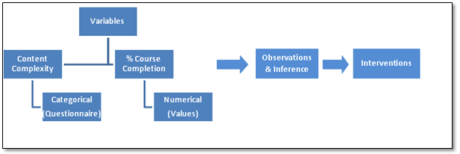
Similarly, you may apply the regression technique to identify the time-frame within which various learners/employees completed the program (relationship between two variables: time-frame and course completion). The regression technique is applied to variables with a numeric value (unlike a categorical value). In the example below, Content Complexity will have a Categorical Value – for example, Very Complex, Moderately Complex and Simple. In the same example, if you wanted to know what percentage of learners is likely to complete the program, you would use a regression model. To do so, simply supply data from current and past learners with their course completion status as the target value, and a regression model will be built on that build/training data. Once run on the new learners, the regression model will match attribute values with predicted course completion rates and assign the predictions to each learner accordingly.
Classification:
- Program Drop-out/Not Drop-out
- Content Complexity: Very Complex, Moderately Complex and Simple
Regression:
- Relationship between two variables
- Given a time-frame what percentage of learners will complete the course?
- Course Completion percentage: 25% in 1 month; 50% in 2 months; 90% in 3 months
The Clustering technique may be applied to find groups with natural similarities. This is used when there are no obvious natural groupings, in which case the data may be difficult to explore. Clustering the data can reveal groups and categories you were previously unaware of. These new groups can then be used for further data mining operations from which you may discover new correlations. To continue with our example, through clustering you may be able to find a new pattern – for example, most of the learners who drop out are mid-level managers.
Integrating Analytics with LMS
You can use applications with your LMS to track, monitor and publish reports. One example is the Open Academic Analytics Initiative (OAAI), used by educational institutions. This is an “open-source academic early-alert system that can predict (with 70–80% accuracy) within the first two or three weeks of a semester which students in a course are unlikely to complete the course successfully.” There are also third party plugins, such as Zoola and SmartKlass, which can be integrated with corporate LMSs to gather learning insights and deliver meaningful reports. Typically, these tools will publish reports with a few significant parameters.
Summary
Learning analytics is not like a turnkey project. It is not that you set it and forget about it. It is an ongoing and iterative activity, and the real impact from it comes more from the technology is used by the stakeholders and the dialogue it provokes among them.
Here is an article detailing the synergetic skillset that’s needed in learning analytics.
1 responses on "Predictive Learning Analytics"
Leave a Message
You must be logged in to post a comment.
![]()
Tools
Type
Companies
Loved this piece as it enlighted me about the practical application of AI in instructional designing! I never even thought about it before. Thanks for sharing